内存对齐
C/C内存对齐详解
C/C 结构体及其数组的内存对齐
现代计算机中内存空间都是按照 byte 划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但是实际的计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数k(通常它为4或8)的倍数,这就是所谓的内存对齐。
内存对齐规则
每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。gcc中默认#pragma pack(4),可以通过预编译命令#pragma pack(n),n = 1,2,4,8,16来改变这一系数。不能用一些奇怪的数,比如3,vscode报错了,但vstudio没报错,怀疑是强转了。
有效对其值:是给定值#pragma pack(n)和结构体中最长数据类型长度中较小的那个。有效对齐值也叫对齐单位。
了解了上面的概念后,我们现在可以来看看内存对齐需要遵循的规则:
(1) 结构体第一个成员的偏移量(offset)为0,以后每个成员相对于结构体首地址的 offset 都是该成员大小与有效对齐值中较小那个的整数倍,如有需要编译器会在成员之间加上填充字节。
(3) 结构体的总大小为 有效对齐值 的整数倍,如有需要编译器会在最末一个成员之后加上填充字节。
1 |
|
windows debug 86
1 | 10ff7d8 |
#pragma pack(4) ,
windows debug 86
1 | f5fadc |
#pragma pack(1)即各变量内存总和
结构体内的数组(如int a[10])可以认为连续有10个int的变量。
1 |
|
C与指针:根据边界对齐要求降序排列结构体成员可以最大限度减少存储中浪费的内存空间。
union
参考:C与指针211页
union,中文名“联合体、共用体”,在某种程度上类似结构体struct的一种数据结构,共用体(union)和结构体(struct)同样可以包含很多种数据类型和变量。
一个联合体的所有成员都存储在内部的同一位置,通过访问不同类型的联合成员,内存中相同的位组合可以被解释为不同的东西,联合在实现变体记录(内存中某个特定的区域将在不同的时刻存储不同类型的值)时很有用,但程序员必须负责确认实际存储的是那个变体并选择正确的联合成员以便访问数据。联合变量也可以进行初始化,但初始值必须为联合第一个成员的类型匹配(如果不匹配的话编译器会强转,可能的话,如double->int)。
区别:
结构体(struct)中所有变量是“共存”的——优点是“有容乃大”,全面;缺点是struct内存空间的分配是粗放的,不管用不用,全分配。
而联合体(union)中是各变量是“互斥”的——缺点就是不够“包容”;但优点是内存使用更为精细灵活,也节省了内存空间(一般不用数组,用指针代替数组,这样就不会又太大的变量)。
union联合体所有数据成员共享一段内存,后写入的成员数据将覆盖之前的成员数据,成员数据都有相同的首地址。
- 内存对齐规则:没找到,自己猜的,以最大的变量(数组算总长度)为内部内存占的空间,然后按结构体的内存对齐思想,找内部最大的类型(数组算单个长度)和#pragma pack(n)中最小的,以此倍数补齐。
1 |
|
1 |
|
位段/位域(bit field)
参考:C与指针
http://c.biancheng.net/view/2037.html


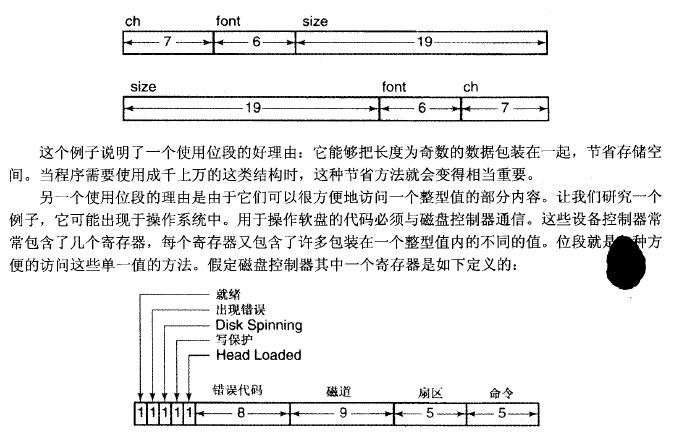


如果冒号后面不加位数,会自动按类型的原本长度如int,char等分配。
概要:
- 移植性
- signed unsigned
- 内存分配方向
- 操作系统位数,位段最大长度(不能超过类型长度int,char等)
总结:位段允许长度为奇数的一些值包装在一起以节省存储空间,源代码如果需要访问一个值内部的一些位,使用位段比较简单(也可以通过移位和屏蔽实现,目标代码中两种实现方式无区别),位段是结构的一种,但它的长度以位为大卫指定,位段声明在本质上是不可移植的(也能移植,但需要考虑太多因素)
百度
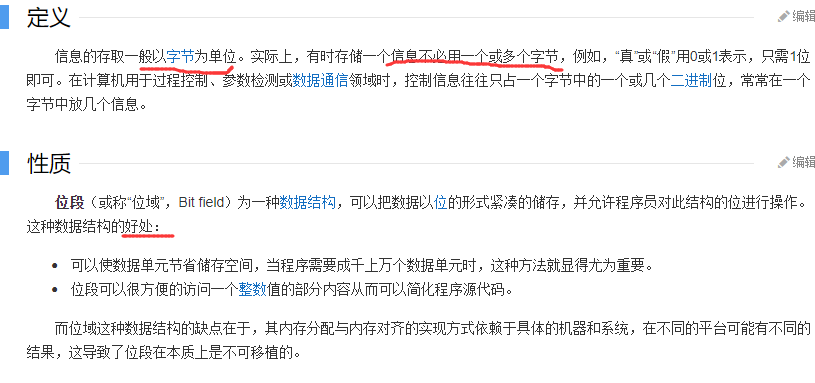

例题
1 |
|
C 库宏 offsetof(type, member-designator) 会生成一个类型为 size_t 的整型常量,它是一个结构成员相对于结构开头的字节偏移量。成员是由 member-designator 给定的,结构的名称是在 type 中给定的
以下运行结果和我预想的不一致,没搞明白,有时间再看。就是结构体各首地址应该多少?为什么和分配内存对齐的结果不一致,难道是因为地址这样做方便程序员不考虑内存对齐就可以用指针指向具体成员?内部系统自己再转换成对齐后的地址???
1 | cout << (int)offsetof(struct data1, m) << endl;//0 |
1 | printf("%d\n", &test); |
1 | 6340928 |

